#7543 closed Bug (invalid)
Invalid handling of unclosed list items with link at the end
| Reported by: | Sa'ar Zac Elias | Owned by: | |
|---|---|---|---|
| Priority: | Normal | Milestone: | |
| Component: | Core : Parser | Version: | 3.0 |
| Keywords: | Cc: |
Description
Using Chrome, go to source and paste:
<ul> <li> This is some <strong>sample text</strong>. You are using <a href="http://ckeditor.com/">CKEditor. </ul>
Expected:
<ul> <li> This is some <strong>sample text</strong>. You are using <a href="http://ckeditor.com/">CKEditor.</a></li> </ul>
Result:
<ul> <li> This is some <strong>sample text</strong>. You are using <a href="http://ckeditor.com/">CKEditor. </a></li> </ul> <p> <a href="http://ckeditor.com/"> </a></p>
Not a recent regression. Didn't try Safari.
Attachments (5)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (14)
comment:1 Changed 15 years ago by
| Component: | General → Core : Parser |
|---|
comment:2 Changed 15 years ago by
| Keywords: | Webkit added; Chrome removed |
|---|---|
| Status: | new → confirmed |
| Version: | → 3.0 |
comment:3 Changed 14 years ago by
Just wondering, is this bug on any roadmap at all? It's caused some fairly nasty tangles in our app, and I haven't yet worked up the chops to fix it myself yet.
For reference: https://bugzilla.mozilla.org/show_bug.cgi?id=775952#c29
comment:4 Changed 14 years ago by
| Keywords: | Webkit removed |
|---|---|
| Resolution: | → invalid |
| Status: | confirmed → closed |
I have looked more closely into this issue and it seems invalid.
This is how browser (without any CKEditor logic) sees this code right after loading the page.
<ul> <li> This is some <strong>sample text</strong>. You are using <a href="http://ckeditor.com/">CKEditor. </a></li></ul> <a href="http://ckeditor.com/"></a>
See the anchor at the end.
The browser itself generates such bad HTML and since there is no way for JavaScript to get to this code before browser does there is nothing we can do to fix it. CKEditor receives code with extra anchor after the list and all it can do is wrap it into <p> if enter mode is set to paragraph.
@lmorchard your test case is the same. It's the browser ho first "breaks" HTML. By writing breaks I've meant it produces code that you don't expect but this is in fact your fault because you provide browser with such code.
IMHO this is quite an edge case and the simplest fix/workaround is to provide closed tags.
comment:5 Changed 14 years ago by
The problem is that CKEditor mucks up the content before we can even edit it to insert the closing tags. The transition from WYSIWYG to source and back introduces the issue. Basically, we have to edit this stuff by hand with MySQL, or build a page to edit without CKEditor enabled. We have enough pages in this shape that it's not really an edge case to us.
We still have to get this fixed one way or another, so I guess your marking it invalid means an upstream fix won't be forthcoming.
FWIW, I think the bit about what the browser does is a red herring. As far as I can tell, the parser and writer in CKEditor don't use the browser's parsing facilities. And yet, that's where I've since narrowed this issue down to:
var src = "<h3><a name=\"x-1\">Foo</h3>\n<p>Lorem ipsum</p>\n<p>Dolor amet</p>\n<h3><a name=\"x-2\"/>Bar</h3>\n<p>Bacon bacon bacon</p>\n<h3><a name=\"x-3\">Baz</h3>\n<p>Tofu tofu tofu</p>\n<h3><a name=\"x-4\"></a>Quux</h3>\n<p>Peas peas peas</p>"; var frag = CKEDITOR.htmlParser.fragment.fromHtml(src); var writer = new CKEDITOR.htmlWriter(); frag.writeHtml(writer); var result = writer.getHtml(); console.log(result); /* <h3> <a name="x-1">Foo</a></h3> <p> <a name="x-1">Lorem ipsum</a></p> <p> <a name="x-1">Dolor amet</a></p> <h3> <a name="x-2"></a><a name="x-1">Bar</a></h3> <p> <a name="x-1">Bacon bacon bacon</a></p> <h3> <a name="x-3"></a><a name="x-1">Baz</a></h3> <p> <a name="x-1">Tofu tofu tofu</a></p> <h3> <a name="x-4">Quux</a></h3> <p> <a name="x-4">Peas peas peas</a></p> */
comment:6 follow-up: 7 Changed 14 years ago by
As far as I can tell, the parser and writer in CKEditor don't use the browser's parsing facilities.
Yeah, sure CKEditor gets to the code before browser does. Good one.
Of course CKEditor doesn't use browser parsing facilities but it gets HTML processed by a browser and browser is the one that destroys your code first not CKEditor.
In short this process looks like this:
- You paste this invalid code:
<h3><a name="x-1">Foo</h3> <p>Lorem ipsum</p> <p>Dolor amet</p> <h3><a name="x-2"/>Bar</h3> <p>Bacon bacon bacon</p> <h3><a name="x-3">Baz</h3> <p>Tofu tofu tofu</p> <h3><a name="x-4"></a>Quux</h3> <p>Peas peas peas</p> - Browser (Chrome in this case) changes it into:
<h3><a name="x-1">Foo</a></h3><a name="x-1"> <p>Lorem ipsum</p> <p>Dolor amet</p> </a><h3><a name="x-1"></a><a name="x-2">Bar</a></h3><a name="x-2"> <p>Bacon bacon bacon</p> </a><h3><a name="x-2"></a><a name="x-3">Baz</a></h3><a name="x-3"> <p>Tofu tofu tofu</p> </a><h3><a name="x-3"></a><a name="x-4"></a>Quux</h3> <p>Peas peas peas</p> - Finally CKEditor changes this code into:
<h3> <a name="x-1">Foo</a></h3> <p> <a name="x-1"> </a></p> <p> <a name="x-1">Lorem ipsum</a></p> <p> <a name="x-1">Dolor amet</a></p> <h3> <a name="x-1"></a><a name="x-2">Bar</a></h3> <p> <a name="x-2"> </a></p> <p> <a name="x-2">Bacon bacon bacon</a></p> <h3> <a name="x-2"></a><a name="x-3">Baz</a></h3> <p> <a name="x-3"> </a></p> <p> <a name="x-3">Tofu tofu tofu</a></p> <h3> <a name="x-3"></a><a name="x-4"></a>Quux</h3> <p> Peas peas peas</p>
This is because it treat anchors as inline elements (The HTML4 way because CKEDitor 3.x is mainly HTML4 or more precisely XHTML1.1 compliant). We are working on block-level links but that is completely different story.
Having said all that, where is CKEditor fault? Could you show or explain it to me?
comment:7 Changed 14 years ago by
Replying to j.swiderski:
As far as I can tell, the parser and writer in CKEditor don't use the browser's parsing facilities.
Yeah, sure CKEditor gets to the code before browser does. Good one.
I'm guessing that, yes, it does that when I:
- Click "source"
- Paste the markup into the textarea
- Click "source" again
Of course CKEditor doesn't use browser parsing facilities but it gets HTML processed by a browser and browser is the one that destroys your code first not CKEditor.
No need to be a jerk. I'm not attacking you personally or your code; I'm just trying to fix a problem.
I pasted the code that shows the issue, using just htmlParser and htmlWriter from CKEditor. Like I said, as far as I can tell, it's parsing my markup without using the browser's parser.
Having said all that, where is CKEditor fault? Could you show or explain it to me?
I already showed it to you, in the example code using htmlParser and htmlWriter.
As far as I'm concerned, as a user of the CKEditor code: Some not-great markup gets made even less great. I'd like to stop it from doing that. Clearly you don't see it as a problem, so I'm left to try fixing it myself. Understood, thanks.
Don't bother replying if you're not going to help.
Changed 14 years ago by
| Attachment: | 7543_data_before_loading_html_from_div.png added |
|---|
Changed 14 years ago by
| Attachment: | 7543_div_innerhtml.png added |
|---|
Changed 14 years ago by
| Attachment: | 7543_data_after_loading_html_from_div.png added |
|---|
Changed 14 years ago by
Changed 14 years ago by
| Attachment: | 7543_html.png added |
|---|
comment:8 Changed 14 years ago by
@lmorchard
We have two separate issues here.
- A general rule that says that one cannot expect a valid HTML in output from invalid input, unless the browser itself is able to handle it properly.
- A very specific case that you want to deal with (assuming that you do not expect any other invalid tags). You want to get rid of the link that improperly surrounds the paragraph.
j.swiderski tried to explain the 1) point.
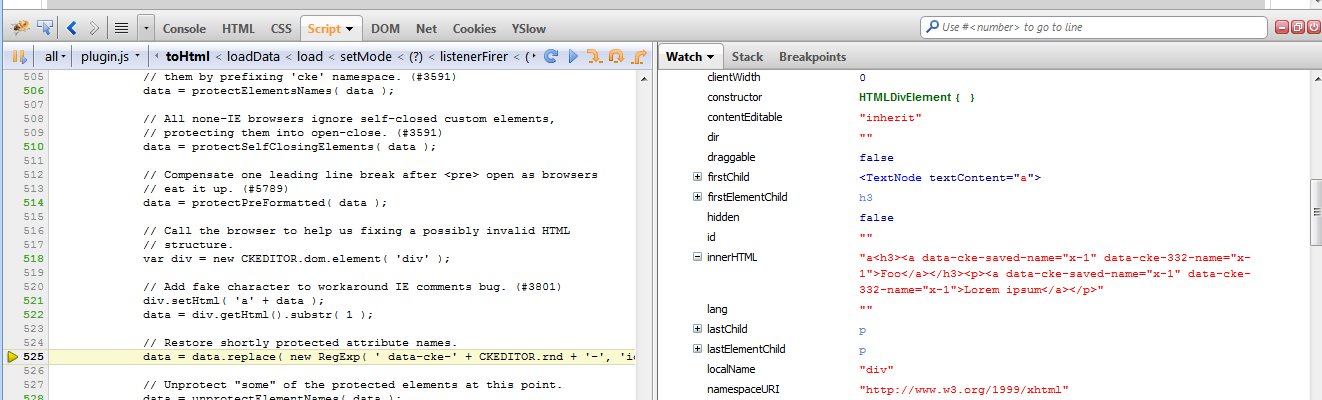
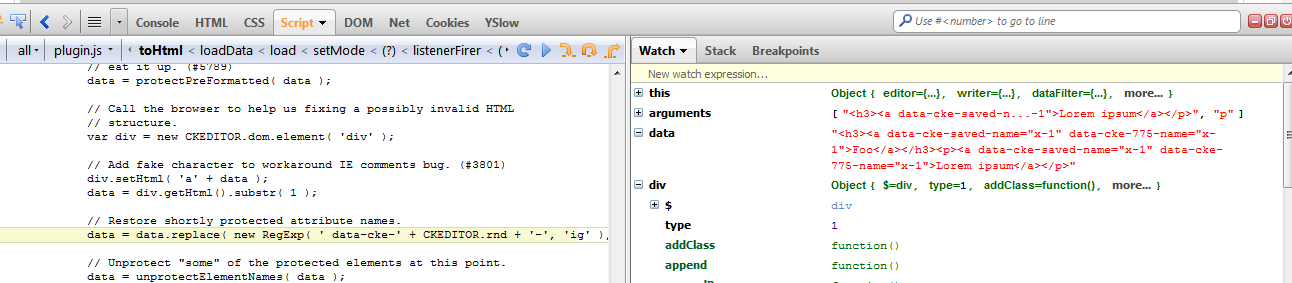
I'll just focus on details to show it's a browser issue. Here are some screenshots from the debugger. Everything happens in the htmldataprocessor plugin:
var div = new CKEDITOR.dom.element( 'div' ); // Add fake character to workaround IE comments bug. (#3801) div.setHtml( 'a' + data ); data = div.getHtml().substr( 1 );
- 7543_data_before_loading_html_from_div.png
- 7543_div_innerhtml.png
- 7543_data_after_loading_html_from_div.png
Okay, it's still a CKEditor plugin. Let's use a pure JavaScript code:
var src = "<h3><a name=\"x-1\">Foo</h3>\n<p>Lorem ipsum</p>";
var div = document.createElement("div");
div.innerHTML = src;
document.body.appendChild(div);
console.log(div.innerHTML);
The result in Firefox / Chrome:
<h3><a name="x-1">Foo</a></h3><a name="x-1"> <p>Lorem ipsum</p></a>
The link element surrounds the paragraph. No CKEditor involved in this issue.
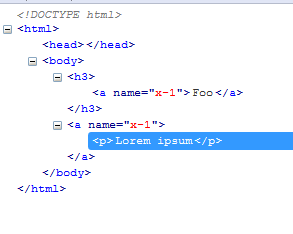
in fact, if you take a pure HTML document (7543.html) and inspect it in Firebug, you will see that the link is added by the browser:

The only thing that CKEditor does is that it moves inline elements inside block elements (a link into the paragraph element). But as far as I understood, the problem is that the link tag is repeated in the document, so that does not change anything.
Now the 2) point
Fixing broken HTML is a tough thing, but if you are sure that you have to deal with some certain cases, there is a way to fix the HTML code entered in source mode, before CKEditor will switch to wysiwyg mode.
var editor = CKEDITOR.replace( 'editor1', {extraPlugins: 'fixtags'} );
CKEDITOR.plugins.add( 'fixtags',
{
afterInit : function( editor )
{
var proto = CKEDITOR.htmlDataProcessor.prototype;
proto.toHtml = CKEDITOR.tools.override( proto.toHtml, function( org )
{
return function( data )
{
console.log("DATA before", data);
data = data.replace( /<a name="x-1">Foo/gi, '<a name="x-1">Foo</a>' );
console.log("DATA after", data);
return org.apply( this, arguments );
};
});
}
});
this is a sample code that this particular plugin is able to deal with:
<h3><a name="x-1">Foo</h3><p>Lorem ipsum</p>
The output is:
DATA before <h3><a name="x-1">Foo</h3><p>Lorem ipsum</p> replac...de.html DATA after <h3><a name="x-1">Foo</a></h3><p>Lorem ipsum</p>
and the final HTML produced by CKEditor is:
<h3> <a name="x-1">Foo</a></h3> <p> Lorem ipsum</p>
comment:9 Changed 14 years ago by
No need to be a jerk. I'm not attacking you personally or your code; I'm just trying to fix a problem.
@lmorchard sorry for my last comment. It was not my intention to offend you.
As @wwalc has explained I only wanted to say (didn't choose the best way for it) that browser changes this code before CKEditor even sees it. Perhaps I should have also suggested opening page with this code without CKEditor logic.
Despite it sounds stupid the best solution here is to close tags. If you can't do that and have limited number of such cases then I hope that method provided by @wwalc will help.
Happens in both Safari and Chrome